前言
话说,今年5月份安利hzk来参加leetcode的周赛的时候,被反安利了一波阿里云的中间件挑战赛,不过今年换了个名字,叫云原生编程挑战赛。不过hzk忙着结婚,把我拉进坑自己却跑了。对于这种偏工程化的比赛,之前从未参加过,便打算试试。由于工作比较忙的缘故,大概是花了两个月的时间,在每天下班后抽时间写bug,改bug。期间走了不少弯路,一直到比赛结束,还有些优化没来得及写,但总的来说,对个人的提升还是很大的。趁着国庆这个假期,把这次项目总结一下。
题目介绍
题目是让实现一个基于tail-based采样的分布式链路追踪系统。其中涉及到两点概念:
1.分布式链路追踪系统。该系统用来记录请求范围内的信息,用户在页面的一次点击发送请求,这个请求的所有处理过程,比如经过多少个服务,在哪些机器上执行,每个服务的耗时和异常情况。
2.Tail-based采样。这种采样是指只采集有具体特征的数据,比如错慢全采,大客户全采。
下图是官方给出的流程图
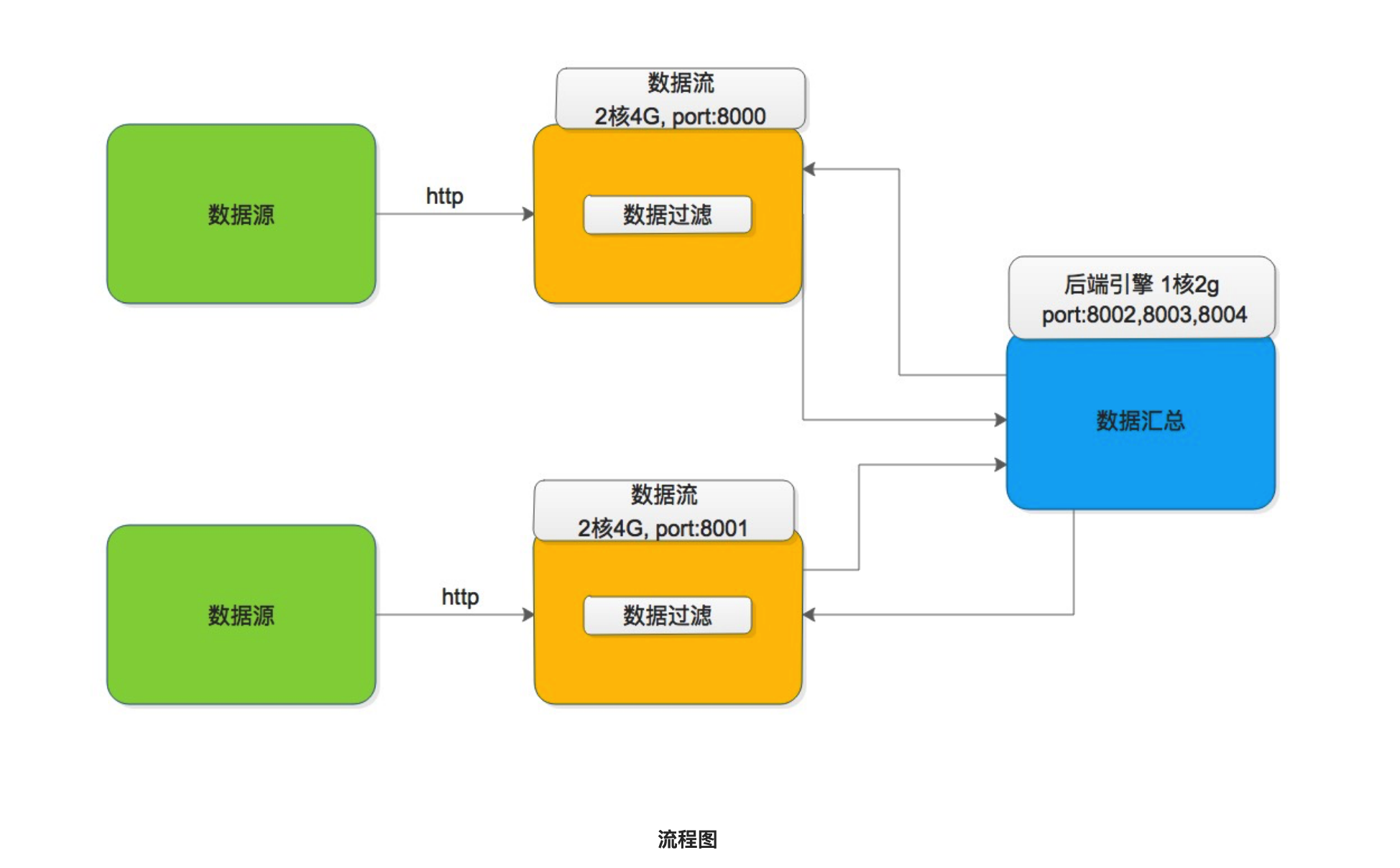
下面是官方给出的文件中的数据样例
d614959183521b4b|1587457762873000|d614959183521b4b|0|311601|order|getOrder|192.168.1.3|http.status_code=200
d614959183521b4b|1587457762877000|69a3876d5c352191|d614959183521b4b|305265|Item|getItem|192.168.1.3|http.status_code=200
d614959183521b4b|1587457763183000|dffcd4177c315535|d614959183521b4b|980|Loginc|getLogisticy|192.168.1.2|http.status_code=200
d614959183521b4b|1587457762878000|52637ab771da6ae6|d614959183521b4b|304284|Loginc|getAddress|192.168.1.2|http.status_code=200
每个节点一份数据文件。数据格式进行了简化,每行数据(即一个span)包含如下信息:
traceId | startTime | spanId | parentSpanId | duration | serviceName | spanName | host | tags
具体各字段的:
- traceId:全局唯一的Id,用作整个链路的唯一标识与组装
- startTime:调用的开始时间
- spanId: 调用链中某条数据(span)的id
- parentSpanId: 调用链中某条数据(span)的父亲id,头节点的span的parantSpanId为0
- duration:调用耗时
- serviceName:调用的服务名
- spanName:调用的埋点名
- host:机器标识,比如ip,机器名
- tags: 链路信息中tag信息,存在多个tag的key和value信息。格式为key1=val1&key2=val2&key3=val3 比如 http.status_code=200&error=1
要求
找到所有tags中存在 http.status_code 不为 200,或者 error 等于1的调用链路。输出数据按照 traceId 分组,并按照startTime升序排序。记录每个 traceId 分组下的全部数据,最终输出每个traceId下所有数据的CheckSum(Md5值)。
注意:一条链路的数据,可能会出现两个数据流中,例如span在数据流1中,parentSpan在数据流2中。 当数据流1中某个span出现符合要求时,那对应的调用链(相同的traceId)的其他所有span都需要保存,即使其他span出现在数据流2中。相同traceId的第一条数据(span)到最后一条数据不会超过2万行。
题目理解与分析
下面的流程图是我按个人理解画的流程图
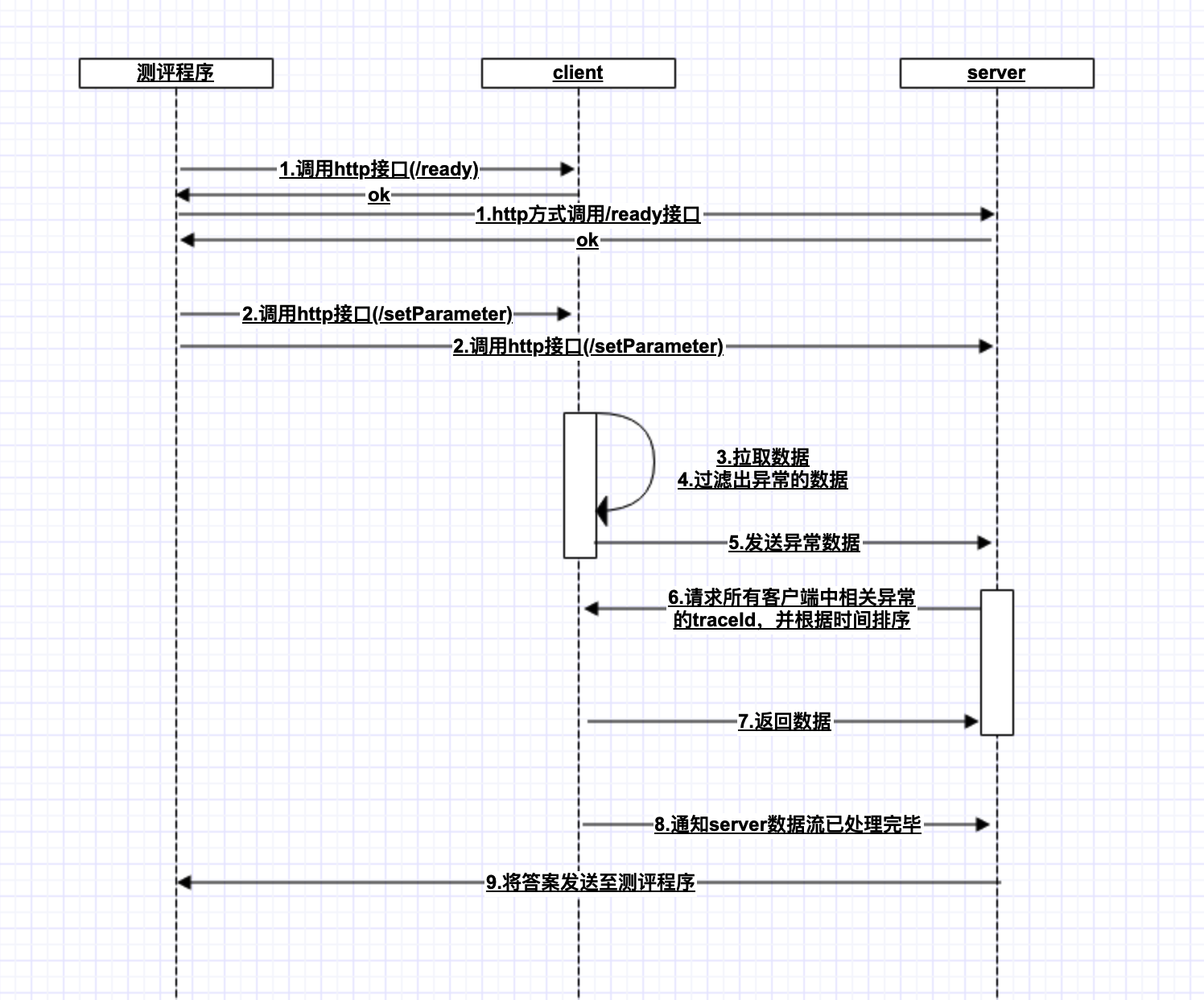
可以看出,我们开发以及优化的点集中在3,4,5,6,7这几个步骤中。总结下:
1.快速从输入流中读取数据
2.快速从读取的数据中过滤出异常的行
3.server根据接收到client端传送过来的traceId,再从两个client端获取到异常traceId所对应的完整的数据
4.对每个异常的traceId对于的完整的数据根据其中的时间字段进行排序以及md5
5.client端的数据缓存、同步。因为输入流肯定大于本机内存,所以肯定要考虑做流式处理。
由于我们只考虑异常的数据,所以网络开销很有限,我们优化的侧重点要放在client端,以及相关的数据的搜索
具体实现
1.存储模型
因为考虑到相同traceId的第一条数据(span)到最后一条数据不会超过2万行,client端通过List<Map<TraceId, List<byte[]»>和水位标记clusterHw来做数据缓存和同步。list固定长度为10,相当于缓存了10*5M=50M的数据。
2.线程模型
client端主要有两个线程,第一个线程用于数据的读取以及数据的搜索,然后将对应的(byte数组,每一条span的起始下标,该span是否为异常span)添加到阻塞队列Q中,第二个是处理线程,用于消费阻塞队列中的数据,并发送异常的traceId给server
3.通信模式
client节点和server节点之间,使用netty来做tcp长连接通信。
4.数据读取
最初数据的读取,我采用的是BufferedReader#readLine()方法,然后对读取出来的String做特征判断。后来发现这种方式效率太低。调整为inputStream#read(byte b[], int off, int len),这样每次都是从输入流中读取5M的内容(因为5M差不多是20000多行的内容)
5.特征数据查找
这里查找包含两个内容,给定一个byte[],找到其中每一个span的起始下标,以及确定该span是否为异常的span。其中根据数据的特征做了一些特征优化,提升了不少效率。这里最初有尝试过使用kmp来进行匹配,但效率真的很感人,连String.indexOf()都没比过。最后通过dfs+特征优化,能跳就跳,将时间复杂度从O(n)优化到O(n/3)左右
6.数据流式处理
在第1点中提到了client中缓存了105M的数据,这边就是通过两个忙轮询来实现了数据的流式处理。每组数据是5M,那么第i组数据能被删除的充要条件就是client端已经处理完第i+1次的server端的回查,因为为了防止漏数据,在回查第i+1组的异常的traceId的时候,我们会从第i组以及第i+2组中找到对应的数据。那么对应的两个忙轮询就是1.client处理数据并放入List<Map<TraceId, List<byte[]»>时,该Map必须为空;2.在查询第i+1组的异常traceId时,第i+2组的数据必须已经处理完成。对应代码如下
tmp = traceMapList.get(dataProcessService.pos.incrementAndGet() % PARTITION);
while (tmp.size() > 0) {
Thread.sleep(5);
}
private HashMap<Integer, List<byte[]>> copyMap(int oriPos){
if (oriPos < 0) {
return new HashMap<>();
}
while (oriPos >= this.pos.get()) {
try {
// noeProcessSleepCnt.incrementAndGet();
Thread.sleep(5);
} catch (Exception e) {
}
}
return traceMapList.get(oriPos % 10);
}
7.Jvm参数优化
调高新生代大小,因为流式处理,所以对象存活时间短,要避免发生full gc。另外使用Parallel垃圾收集器,提高系统的吞吐量。
8.程序预热,触发JIT
在正式开始跑之前(即调用setParameter接口之前),先跑一遍预热程序,触发C2编译器,将热点代码直接编译成机器代码,提高程序运行效率
9.使用JNI来提高性能
代码中涉及到数组拷贝的地方都使用了System.arrayCopy()来提高效率
10.减少对象的创建
为了降低对象新建和销毁,从数据读取开始到最后上报结果,都是直接操作byte,中间使用任何的String
11.使用volatile关键字
对于很多单线程写,多线程读的变量,都使用了volatile关键字来保证内存可见性,保证了线程安全
12.使用合理的排序
由于要求是按startTime进行升序排序,但该场景中,其实startTime是基本有序的,所以采取的排序策略是:client端进行插入排序,时间复杂度接近O(N),在Server端使用合并排序来合并两个有序序列,时间复杂度为O(N)
最后成绩以及待改进的点
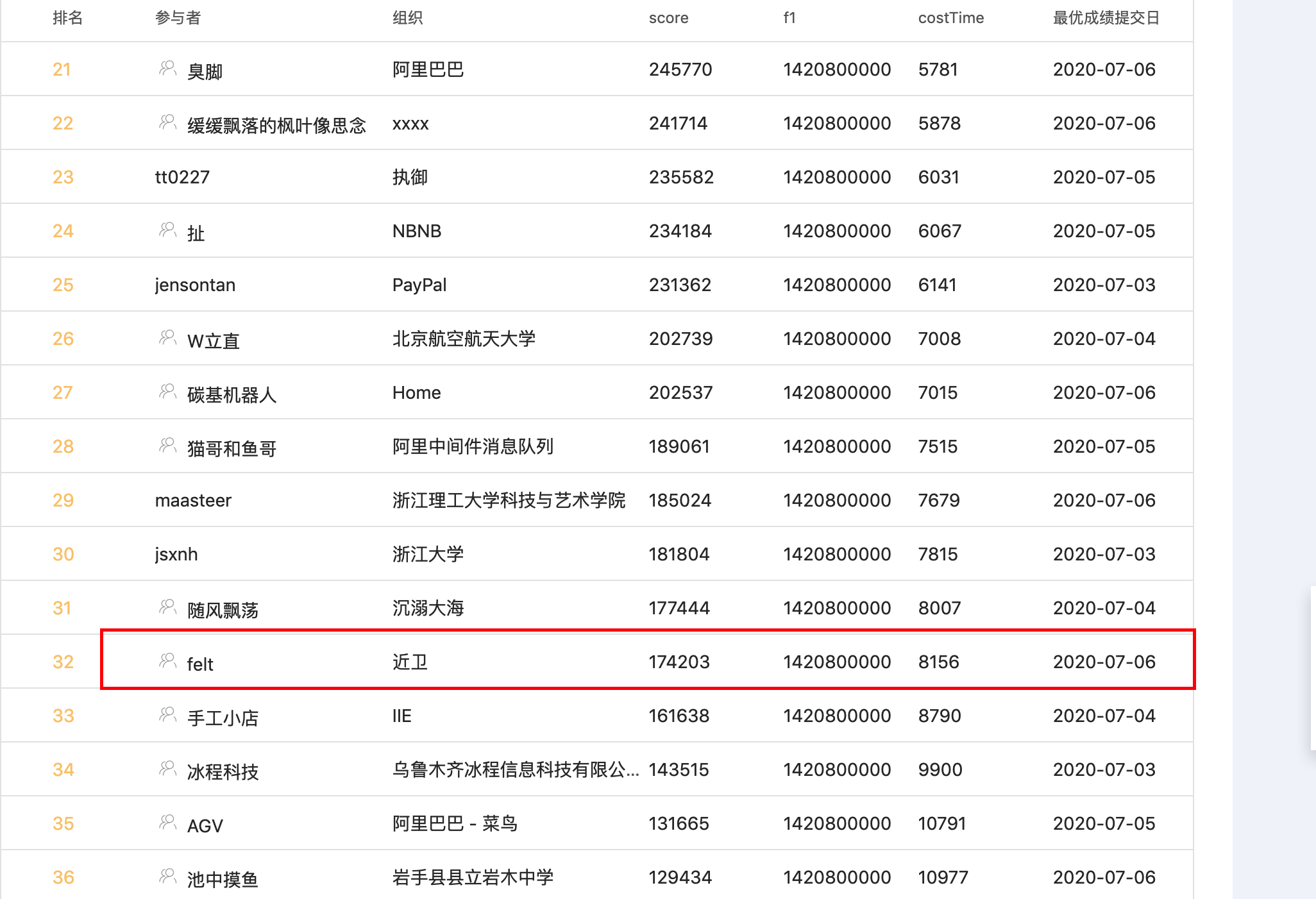
最后的成绩是在32名,处理总共12.8G的数据(每个client处理6.4G)花了8.156秒。后面想想其实还是有些可提升的空间,但早期努力错了方向,没有get到重点,赛程后半段没有太多的时间进行调整了。后面看比较靠前的选手的思路,在我原有程序的基础上,发现还是有些可以优化的点。
1.使用原始集合库
Java中的原生集合确实很好用,但它不能作用于原始类型,这一定程度上降低程序的效率(增加内存使用以及垃圾收集器的开销),比如开源的HPPC,其中就有一系列针对于原始类型的集合。
2.减少内存拷贝
虽然程序中用了JNI来进行数组的拷贝,但后面想想完全可以减少好多次数据的拷贝。之前的数据结构为List<Map<TraceId, List<byte[]»>,其时可以拆成一个byte[50 * 1024 * 1024]的数组,存放映射关系的List也可以改为*List<Map<TraceId, List
3.抛弃springboot
抛弃框架
另外,在这种特别注重性能的比赛场景下,计算机语言还是对最后的成绩有一些影响,最优秀的Java选手也就在15名左右。突然想起以前acm比赛,C的超时时间都是1s,而java都是2s(留下了没技术的泪水)。特此记录下参加的第一场工程类的编程比赛。